题目

题目中得到的信息有
一段字符串找出不重复子串的最大长度,只需要长度信息。
思路
肯定是需要将字符串遍历一遍,在遍历过程中就需要查找前面字符串是否出现该字符,因此这是该算法的重点。若没找到,长度加一,若找到了,长度会从前面该字符位置+1处开始算起。下面以图来说明:
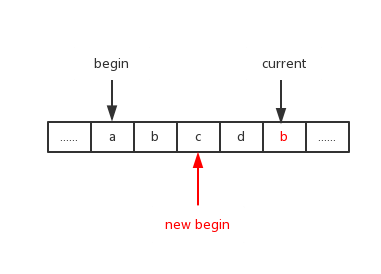
假如我们以begin为子串的开始,current表示当前处理的位置。1)当前位置的字符没有出现在[begin,current)的区间内,说明将该值加入到区间内满足没有重复条件,长度加一; 2)若当前值已经在该区间内,加入后肯定会出现重复,则应该将begin移动到没有该值的最左边位置,图中 new begin位置满足该条件。
在移动begin之前首先需要判断[begin, current)是否是现有的最大长度,若是则更新,然后将begin移动到该新位置。
还有一个关键点,就是如何查找当前字符是否出现在[begin, current)区间里,若在从该区间遍历一遍肯定费时间,有没有办法可以一次就能判断出来呢? 对了,可以采用hash的思想,将每个值在字符串的位置放入到以该值为下标的数组中,若数组中保存有值,并且是在[begin,current)范围内,则说明存在。
C算法
int lengthOfLongestSubstring(char* s) {
int tmp[128]; //用于保存字符的下标
int begin = 0, max = 0; //begin和最大长度默认为0
int i, index;
for (i = 0; s[i] != '\0'; i++) { //遍历字符串
if (tmp[s[i]] != 0) { //判断该值是否出现在前面的字符中
index = tmp[s[i]] - 1; //取保存的上一个该值的位置
if (index >= begin) { //判断是否在[begin, current)
if (i - begin > max) //对比是否最大
max = i - begin;
begin = index + 1;//begin新的位置,在前一个该字符的后面,即new begin位置
}
}
tmp[s[i]] = i + 1; //保存该值的最新下标
}
return i - begin > max ? i - begin : max;//最后还需要判断下
}
结果
PREVIOUSandroid签名证书文件的解析和签名校验的加强